Published on 04/09/2023 by Kostas Pardalis
Hey, since SaaS is not in vogue anymore, and free tiers for mailing list software are not VC subsidized, for updates just follow us on Twitter: Kostas & Demetrios
This is a series of articles explaining WTF Vector Databases are.
Articles in this series
Dissecting a Vector Database Management System
If you followed the document so far, you have probably noticed the extend I got into to make the distinction between a database and a database management system. To the point that you might even got tired of the focus on the semantics of this article.
But, I did it for a reason! and a good one. It is important to understand that going from some code that can deliver a specific feature, to a whole system that can support different use cases and development scale, is a long long journey.
This is what we will try to demystify in this chapter.
In the previous one we demonstrated how we can build some really cool stuff using vectors and even built the smallest and simplest possible vector database.
Now, we will go through a full vector DBMS and see what makes it so different to the database we built already.
To do that, we will go through the code base of a popular open source vector DBMS named Chroma. The reason we chose this one is because the codebase is clear enough to follow and figure out the features that elevates the project from a database to a full database management system that can be used in production.
Let’s dive in.
What is Chroma
Following the copy on their landing page:
You probably noticed that they use the term “embedding” instead of “vector” but as we explained earlier, it is the same thing.
The main difference is in their focus on AI use cases where the NLP derived terminology is dominant because of the success of LLMs (Large Language Models).
The landing page also does a great job in communicating the features of the DBMS.
- It’s simple to use, in python with a JS client too.
- It’s feature rich, you can perform search, filtering and more (this is important!)
- It has integrations, it can easily be used with the rest of the technologies in the ecosystem.
As you can see and if we compare it with what we built in the previous chapter, we already have some pretty big differences between our database and Chroma.
First, our database could only be used in our specific problem. It wasn’t even a library that someone could import to build on top.
We could perform similarity searches but that was all, we didn’t have any way to do stuff like filter based on the speaker or the time window we’d like to search into. That’s some pretty big limitations and it’s a big part of what makes Chroma a real DBMS instead of a very domain-specific database implementation like ours.
Finally, there are integrations. Here we see that Chroma is built as part of a whole ecosystem, the systems it will most often interact with are taken into account in the way the technology has been built and it’s a big part of the experience.
For example, in our case we were using a specific library and model to generate vectors. In Chroma, switching from one model - service to the other, it’s just a parameter change in the function you call (as we will see later).
Chroma is heavily used in AI use cases, for example in creating application on top of technologies like ChatGPT from OpenAI. That’s the reason you see a very specific terminology being used.
Chroma can be used for generic vector database use cases but it’s very clear from the beginning that you will get the best experience when you’ll be using it to build AI applications.
The Data Model
The data model of the DBMS is important, it defines the boundaries of what and how can be modeled in our database system.
In the toy database we built, our data model was very simple. Just a list of tuples containing a vector and an id. The id could technically be used to link the vector with other richer data structures that contain additional information we need.
In our case we were using that to figure out the starting time of the segments we have found.
But our model is too restrictive. We couldn’t easily add arbitrary data to it as we are used in doing with popular database systems. We also couldn’t easily combine similarity search with search in the rest of the data.
For example, how could we limit the search in segments only from a specific speaker?
To address all these limitations and because Chroma aspires to be a generic vector DBMS that can be used for every use case that requires vectors - embeddings, they have designed a simple but pretty expressive data model.
Let’s see how it looks.
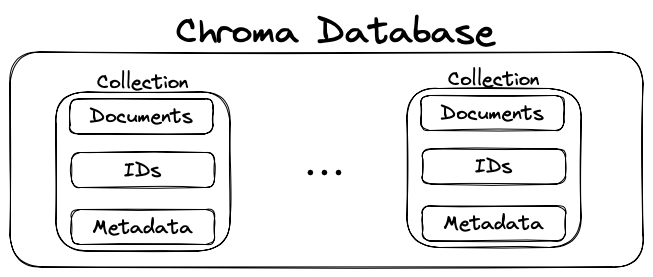
The Chroma Data Model
What do we have here:
- A Chroma database can have an arbitrary number of Collections - think of them as tables in a relational database.
- Each collection consists of documents, IDs that allow us to uniquely identify the documents and associated metadata for the documents. Think of these as the columns of the table. Each document has an ID and a number of metadata associated to it.
This model is not very complicated but it’s much much more expressive than what we were using in our toy database.
We do have Documents (that will turn into vectors internally as we will see) and IDs as we also did, but the addition of arbitrary metadata that someone can incorporate in their queries with operators like “filter” is extremely powerful.
Let’s see how Chroma works.
How Chroma Works
Chroma’s API is simple and elegant, you can find more information in their documentation, but I’ll repeat it here for convenience. The core API is just four functions.
import chromadb
# setup Chroma in-memory, for easy prototyping. Can add persistence easily!
client = chromadb.Client()
# Create collection. get_collection, get_or_create_collection, delete_collection also available!
collection = client.create_collection("all-my-documents")
# Add docs to the collection. Can also update and delete. Row-based API coming soon!
collection.add(
documents=["This is document1", "This is document2"], # we handle tokenization, embedding, and indexing automatically. You can skip that and add your own embeddings as well
metadatas=[{"source": "notion"}, {"source": "google-docs"}], # filter on these!
ids=["doc1", "doc2"], # unique for each doc
)
# Query/search 2 most similar results. You can also .get by id
results = collection.query(
query_texts=["This is a query document"],
n_results=2,
# where={"metadata_field": "is_equal_to_this"}, # optional filter
# where_document={"$contains":"search_string"} # optional filter
)As you can see, we have:
- A way to initialize Chroma
- A way to create collections
- A way to add records in the collection
- A way to query collections
And that’s it. But to understand what’s going on behind the scenes, let’s follow the traces of executing each one of these functions. This will also help us understand what it takes to get from a vector database to a vector database management system.
Chroma Initialization
The first we have to do, is to create a database.
import chromadb
client = chromadb.Client()This is going to create a Chroma database that will drop its data when our application exits. This is great for experimenting but not that far away from the behavior our toy vector database had.
Chroma can do much better than that and this is where we will start witnessing the difference between a database and a DBMS.
We can also do:
import chromadb
from chromadb.config import Settings
client = chromadb.Client(Settings(chroma_db_impl="duckdb+parquet",
persist_directory="/path/to/persist/directory"
))Which will be an in-memory database that will persist data on disk so we can resume the database after an application restart.
What is interesting in the above code snippet, is the setting “chroma_db_impl”. We will talk more about this later.
Finally we have a third option.
import chromadb
from chromadb.config import Settings
chroma_client = chroma.Client(Settings(chroma_api_impl="rest",
chroma_server_host="localhost",
chroma_server_http_port="8000"
))Here we run Chroma in client mode which requires a server to be running at port 8000. This allows us to setup a production database and use a standard client-server architecture between our application and the vector database that manages the application state.
As you can see, Chroma offers a number of different deployment modes.
- One that is good for experimenting
- An embedded version where the vector database is embedded in our application
- A client-server version, where the database runs as the server and our application can connect to it.
You can see from the above how much more complicated it is to create a system that is flexible enough to cover a number of standard use cases.
Chroma backends
We mentioned earlier that Chroma has an interesting setting named “chroma_db_impl”. Chroma does not implement all the different services that a typical database system requires. Instead it relies on third party backends for that.
The current version of Chroma supports two backends.
The choices are interesting and actually you can easily figure out why these particular databases were chosen.
DuckDB is great for the embedded use-case. It is supposed to be used as an embedded analytical database, similarly to SQLite.
Clickhouse is used for the client-server mode. The docker-compose configuration file is very insightful here.
volumes:
- ./:/chroma
- index_data:/index_data
command: uvicorn chromadb.app:app --reload --workers 1 --host 0.0.0.0 --port 8000 --log-config log_config.yml
environment:
- CHROMA_DB_IMPL=clickhouse
- CLICKHOUSE_HOST=clickhouse
- CLICKHOUSE_PORT=8123
ports:
- 8000:8000
depends_on:
- clickhouse
networks:
- netClickhouse is built to operate in a client-server architecture and can scale to the levels such a deployment would require. It also has some of the best developer experience around when it comes to both the features it supports but also the easiness of deploying and operating it, compared to other OLAP systems.
What Chroma has done here is pretty smart. They rely on some very mature database management systems to inherit all the DBMS features that a database needs, while they build on top of them the functionality of storing and processing vector (embedding) data.
In this way they can use the database to store arbitrary metadata together with the vectors and use that information to very efficiently filter the data before expensive vector operations are performed.
It also allows users to create custom schemas using SQL on these systems and easily adapt Chroma to their use cases. In contrast, if we wanted in our toy example to build a different application we would probably have to rewrite most of the vector database logic to accommodate the new requirements we have.
With a full DBMS system, we won’t have to do that!
Also, Chroma doesn’t have to worry about scalability both in terms of concurrency, throughput and latency. These are all taken care by the backend database that is built with that stuff in mind and is highly optimized.
What Chroma has to do though, is to figure out how to add support for vectors and similarity search on these systems, that do not natively have that.
Implementation of the Chroma Data Model
Let’s see how Chroma extends these backend systems to support vector operations and let’s start with how it is done with Clickhouse.
All the magic lives in the implementation of the specific backend here. We will focus on a very small part of the code, see below:
COLLECTION_TABLE_SCHEMA = [{"uuid": "UUID"}, {"name": "String"}, {"metadata": "String"}]
EMBEDDING_TABLE_SCHEMA = [
{"collection_uuid": "UUID"},
{"uuid": "UUID"},
{"embedding": "Array(Float64)"},
{"document": "Nullable(String)"},
{"id": "Nullable(String)"},
{"metadata": "Nullable(String)"},As you can see above, Chroma is actually creating two tables on Clickhouse where the Chroma data model we described earlier is implemented.
There is a table for Collections and then a table where embeddings are stored.
As you can also see, the embedding table is associated with the collection table through the foreign key “collection_uuid”.
The most important type that you have to pay attention at here is “Array(Float64)” that is used as the type of the “embedding” column.
Clickhouse has native support for Arrays which makes it extremely easy to use for storing and working with embeddings - vectors. If you remember, an embedding or vector is just an array of floats after all.
Not all databases have native support for Arrays though. For example, SQLite3 does not have native support for array types and if you would like to store embeddings in SQLite3 you would have to use something like SQLite3’s support for JSON, serialize the embedding as JSON, store it, retrieve it, deserialize etc. etc. Doable but not ideal.
Things are not that different with the DuckDB backend. From an implementation standpoint, the difference (as you can see below) is that Chroma assumes the Clickhouse schema as the reference schema and has implemented logic for transforming it into a DuckDB compatible schema.
def clickhouse_to_duckdb_schema(table_schema):
for item in table_schema:
if "embedding" in item:
item["embedding"] = "DOUBLE[]"
# capitalize the key
item[list(item.keys())[0]] = item[list(item.keys())[0]].upper()
if "NULLABLE" in item[list(item.keys())[0]]:
item[list(item.keys())[0]] = (
item[list(item.keys())[0]].replace("NULLABLE(", "").replace(")", "")
)
if "UUID" in item[list(item.keys())[0]]:
item[list(item.keys())[0]] = "STRING"
if "FLOAT64" in item[list(item.keys())[0]]:
item[list(item.keys())[0]] = "DOUBLE"
return table_schemaYou can see some types flying around here but the most important change we care about is the “embedding” field type, which now changes into “DOUBLE[]”.
Same thing, just different syntax. DuckDB follows a syntax closer to PostgreSQL when it comes to defining arrays, while for Clickhouse we have a parameterized Array type that takes as a parameter the element’s type.
We can argue a lot on what’s the best syntax, but it doesn’t really matter for what we are doing here. At the end, both systems can express the same things and that’s what’s important.
Now that we know how the data model is implemented, let’s see how we can start adding data to the Chroma Vector DBMS.
Adding embeddings - vectors to Chroma
As a reminder of the Chroma API, this is how you can add new data into Chroma.
# We assume we have already created a collection named "collection".
# Add docs to the collection. Can also update and delete. Row-based API coming soon!
collection.add(
documents=["This is document1", "This is document2"], # we handle tokenization, embedding, and indexing automatically. You can skip that and add your own embeddings as well
metadatas=[{"source": "notion"}, {"source": "google-docs"}], # filter on these!
ids=["doc1", "doc2"], # unique for each doc
)This might feel a bit strange as an API for people who are used to the row based operations from SQL. But it’s not hard to figure out what’s happening here.
You provide documents, metadata and ids for each one and Chroma associates them based on the index of the arrays. ( They are really into vectors for sure! 😀 )
Based on the above example, we get the following table:
| id | document | metadata |
|---|---|---|
| doc1 | this is document1 | “{“source”: “notion”}” |
| doc2 | this is document2 | “{“source”: “google-docs”}” |
You might noticed that I used “” for the metadata. The reason I did this is because Chroma is storing the json objects as strings in the databases, regardless of which database is used. Check the previous data model section to see the type used.
You can also see how the JSON is handled by Chroma here.
But, there’s something missing from the above table, right? Where’s the vector of floats??
The following code will be helpful to answer the above question.
def add(
self,
ids: OneOrMany[ID],
embeddings: Optional[OneOrMany[Embedding]] = None,
metadatas: Optional[OneOrMany[Metadata]] = None,
documents: Optional[OneOrMany[Document]] = None,
increment_index: bool = True,
):
"""Add embeddings to the data store.
Args:
ids: The ids of the embeddings you wish to add
embedding: The embeddings to add. If None, embeddings will be computed based on the documents using the embedding_function set for the Collection. Optional.
metadata: The metadata to associate with the embeddings. When querying, you can filter on this metadata. Optional.
documents: The documents to associate with the embeddings. Optional.
ids: The ids to associate with the embeddings. Optional.
"""This is part of the add() method that abstracts the insertion of new records, regardless of which database backend is used. The comment is very helpful.
We can either provide our own embeddings in the form of arrays of floats. In this case these vectors will be added to the table above under the embedding column.
Or we can omit the embeddings and provide only text, and in this case Chroma will generate the embedding from the text.
There are a couple of different options available in Chroma for calculating the embeddings.
Just as in the toy vector database example, someone can use OpenAI or any of the models available on HuggingFace.
The default option for Chroma is to use Sentence Transformers just as we did with the toy vector database.
The huge difference in Chroma though, is that if you want to use OpenAI, you just have to change a flag in a configuration file. While in the toy vector database case, we would have to add additional logic for integrating with OpenAI.
That’s another example of the difference between a database and a DBMS, many auxiliary operations are taken care by the DBMS in an attempt to improve the developer experience.
For Chroma to support arbitrary embedding functions, an embedding function type is introduced. Which in turn relies on another type called Protocol, coming from the Typing library for providing type hints. More for that stuff can be found here.
The interesting thing to keep in mind about the embedding functions, is that in Chroma an embedding function is associated with a collection. Which makes sense right? You really need to use the same embedding function for all the data you will be comparing. This is a way for Chroma to ensure that.
Which again, is another great example of the differences between DBMSs and databases, the DBMS usually will safeguard the user from messing up. In our toy example we could even have vectors of different dimensions mixed together.
Some great examples of how a DBMS is trying to safeguard the user, can be found here.
Finally, all the supported embedding functions are here. As an example of one, see below.
class OpenAIEmbeddingFunction(EmbeddingFunction):
def __init__(self, api_key: str, model_name: str = "text-embedding-ada-002"):
try:
import openai
except ImportError:
raise ValueError(
"The openai python package is not installed. Please install it with `pip install openai`"
)
openai.api_key = api_key
self._client = openai.Embedding
self._model_name = model_name
def __call__(self, texts: Documents) -> Embeddings:
# replace newlines, which can negatively affect performance.
texts = [t.replace("\n", " ") for t in texts]
# Call the OpenAI Embedding API in parallel for each document
return [
result["embedding"]
for result in self._client.create(
input=texts,
engine=self._model_name,
)["data"]
]The above is the implementation for the OpenAI function. You can see the model that is used, some sanity checking for ensuring the dependencies are installed etc. etc. The rest of the implementation is pretty straightforward, each document is submitted to the OpenAI API after removing new lines and the actually embedding is extracted from the response.
Finally, Querying the Embeddings in Chroma
We focused more on the insertion path in the previous section but it is important to mention that Chroma supports the full spectrum of CRUD operations and a lot of the work in building a complete DBMS system goes into supporting all the different operations.
In our toy vector database, we didn’t implement any update or delete operations, instead we assumed that the db is constructed always during startup and it’s immutable. Obviously this cannot serve as a general purpose database management system.
Having said that, let’s see now how we can query the data. Which is the last and probably the most interesting of the API functions of the Chroma Vector Database.
Just as a quick reminder, the way we implemented queries in the toy vector database example was based in iterating the full set of embeddings and calculating the similarity between each stored embedding and the one generated for our query.
Then we would sort the results in ascending order and keep the first K results.
Chroma is doing something similar but it adds much more to what we were doing.
First of all, we can filter using the metadata we provided. For example, based on the example data from the previous section, we might want to search only in documents that are coming from Notion.
The way we would write such a query would look like this:
# Query/search 2 most similar results. You can also .get by id
results = collection.query(
query_texts=["This is a query document"],
n_results=2,
where={"source": "notion"}, # optional filter
)The magic of the query function can be found here, but I’ll also add it here so we can comment on what’s happening.
def _query(
self,
collection_name,
query_embeddings,
n_results=10,
where={},
where_document={},
include: Include = ["documents", "metadatas", "distances"],
):
uuids, distances = self._db.get_nearest_neighbors(
collection_name=collection_name,
where=where,
where_document=where_document,
embeddings=query_embeddings,
n_results=n_results,
)
include_embeddings = "embeddings" in include
include_documents = "documents" in include
include_metadatas = "metadatas" in include
include_distances = "distances" in include
query_result = QueryResult(
ids=[],
embeddings=[] if include_embeddings else None,
documents=[] if include_documents else None,
metadatas=[] if include_metadatas else None,
distances=[] if include_distances else None,
)
for i in range(len(uuids)):
embeddings = []
documents = []
ids = []
metadatas = []
# Remove plural from include since db columns are singular
db_columns = [column[:-1] for column in include if column != "distances"] + ["id"]
column_index = {column_name: index for index, column_name in enumerate(db_columns)}
db_result = self._db.get_by_ids(uuids[i], columns=db_columns)
for entry in db_result:
if include_embeddings:
embeddings.append(entry[column_index["embedding"]])
if include_documents:
documents.append(entry[column_index["document"]])
if include_metadatas:
metadatas.append(
json.loads(entry[column_index["metadata"]])
if entry[column_index["metadata"]]
else None
)
ids.append(entry[column_index["id"]])
if include_embeddings:
cast(List, query_result["embeddings"]).append(embeddings)
if include_documents:
cast(List, query_result["documents"]).append(documents)
if include_metadatas:
cast(List, query_result["metadatas"]).append(metadatas)
if include_distances:
cast(List, query_result["distances"]).append(distances[i].tolist())
query_result["ids"].append(ids)
return query_resultThe first thing the query function does is to execute the function “get_nearest_neighbors()” This function is defined inside the database backend implementation. The important thing here is that this function after some checks, calls the get_nearest_neighbors(embeddings, n_results, ids).
This function is very important and it’s what makes Chroma and the rest of the Vector DBMS practical database systems.
If you remember from the toy vector database implementation, going through all the vectors and calculating similarities is an expensive operation. It would very quickly make our database system impractical if we had to rely on this method for similarity searches.
Instead of that, Chroma and the rest of the Vector DBMSs are implementing what is called an index.
An index is a data structure that allows us to search more efficiently. Indexes are nothing new, if you ever used a database you have definitely encountered them as a way to improve the performance of the database.
Also, you might remember from our conversation about Lucene, that this is also an index, its actual name is an “inverted index”.
Something similar we do here with embeddings but as we are operating in highly dimensional algebraic spaces, we need to use some specialized data structures that can help us balance performance versus precision.
Actually what we will be doing is that we will sacrifice some of the precision of our measurements in order to improve substantially our performance.
The algorithm used for this is nothing new. It was first developed in 1951! Its name is also probably familiar to you from your college years (if you studied CS).
💡 Let me introduce you to the k-nearest neighbors algorithm.
All the Vector DBMSs are using some kind of flavor of the k-nearest algorithm, to speed up similarity searching.
In the case of Chroma the algorithm used is called Hierarchical Navigable Small Worlds (HNSW). What a name, right!
A popular implementation can be found here and it’s the one used by Chrome too. You might also want to check FAISS from Meta, which includes many algorithms together with an implementation of HNSW.
Finally, if you are interested in general about ANN algorithms, I would recommend to check this benchmark repository for KNN algorithms.
Going back to the implementation again, let’s see how the index is used.
Chroma is generating the index for the whole collection. So, an index is attached to each collection of documents. First an index is initialized and after that we can add or delete documents from the index.
So, as the user adds and removes records inside a collection, Chroma ensures that the index is always up to date.
Going back to our query code snippet and assuming that we have an index in place. Chroma will:
- Query the database backend if a “where” clause exists and retrieves the subset of documents we are interested in.
- Searches into the index for the k most similar vectors to our query vector.
- If a where clause was used, the index will be adapted to searching only among the relevant documents.
- A set of document ids together with associated distances are returned to the user.
And that’s it.
That’s how Chroma builds a layer to support similarity search using embeddings on top of popular DBMS backends like Clickhouse and DuckDB.
WTF?
Let’s summarize WTF we’ve been talking so far about.
→ Vector Databases are regular databases that add support for a special data type, a vector.
→ Vector Databases also add support for special operations for these types, specifically a similarity operator.
→ Vector databases care a lot about performance because similarity calculations are expensive.
→ To be performant, Vector Databases rely on filtering first using standard SQL where clause syntax and then use indexing for speeding up the similarity calculations.
→ Indexing is based on recent improved variations of the k-nearest neighbor algorithm.
→ Speed ups with these indexing techniques are coming from being approximate algorithms, allowing the user to trade accuracy for speed.
Written by Kostas Pardalis
← Back to blog

